
Biography
He is now a Full Professor and a Ph.D. Advisor at the School of Computer Science and Technology, China University of Mining and Technology (CUMT). He received the Ph.D. degree in Computer Science and Technology from the Shanghai Jiao Tong University (SJTU) in Aug. 2020, and works as a postdoctoral fellow at the SJTU since Dec. 2022, both with Prof. Lizhuang Ma as the advisor. Also, he works as a postdoctoral fellow at The Hong Kong University of Science and Technology (HKUST) from Jan. 2024 to Dec. 2025, advised by Prof. Dit-Yan Yeung. From Nov. 2017 to Nov. 2018, he was a joint Ph.D. student at the Multimedia and Interactive Computing Lab, Nanyang Technological University (NTU), advised by Prof. Jianfei Cai. Before that, he received the B.Eng. degree in Computer Science and Technology from the Northwestern Polytechnical University (NPU) in Jul. 2015. He has been sponsored with fundings such as Hong Kong Scholars Program, General Project and Young Scientists Fund of the National Natural Science Foundation of China, High-Level Talent Program for Innovation and Entrepreneurship (ShuangChuang Doctor) of Jiangsu Province, and Talent Program for Deputy General Manager of Science and Technology of Jiangsu Province. He has published more than 80 academic papers in popular journals and conferences. He has been serving as an area chair for ACM MM, an associate editor for TVC, a publication chair for CGI, as well as a program committee member or a reviewer in top journals and conferences such as IEEE TPAMI/TIP/TMM, IJCV, CVPR, ICCV, ECCV, AAAI, and ACM MM. His research interests lie in Interdisciplinary Fields of Computer Vision. The official faculty websites can be found here and here. [ Résumé ]
News
July 2026: I am awarded as Top Ten Outstanding Young Faculties of the China University of Mining and Technology.
Dec. 2025: Our paper Spatio-Temporal Disentanglement and Constrained Self-Attention for Multi-Modal Deception Detection is accepted by ACM TOMM.
Oct. 2025: Our paper CurvNet: Latent Contour Representation and Iterative Data Engine for Curvature Angle Estimation is accepted by Pattern Recognition.
Sept. 2025: Our paper Micro-Expression Recognition via Fine-Grained Dynamic Perception is accepted by ACM TOMM.
July 2025: Our paper TextRSR: Enhanced Arbitrary-Shaped Scene Text Representation via Robust Subspace Recovery is accepted by IEEE TMM.
June 2025: Our paper MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution is accepted by IEEE TPAMI.
May 2025: Our paper Constrained and Directional Ensemble Attention for Facial Action Unit Detection is accepted by Pattern Recognition.
May 2025: Our paper Mirror Detection via Multi-Directional Similarity Perception and Spectral Saliency Enhancement is accepted by IEEE TCSVT.
Dec. 2024: I am a recipient of Young Academic Leader Program of the China University of Mining and Technology.
Dec. 2024: We obtain Best Student Paper Award in 2024 CSIG Conference on Emotional Intelligence.
Oct. 2024: I am a recipient of The 3rd National Youth Skilled Worker in the Coal Industry.
Sept. 2024: Our paper Facial Action Unit Detection by Adaptively Constraining Self-Attention and Causally Deconfounding Sample is accepted by IJCV.
Aug. 2024: I am a recipient of General Project of National Natural Science Foundation of China.
May 2024: I am a recipient of First Prize for Technological Achievement of Department of Education of the Henan Province.
Jan. 2024: I serve as an Area Chair in ACM International Conference on Multimedia (MM) 2024.
Jan. 2024: I am now studying at The Hong Kong University of Science and Technology (HKUST) as a postdoctoral fellow, advised by Prof. Dit-Yan Yeung.
Nov. 2023: I serve as an Associate Editor in The Visual Computer.
Aug. 2023: I am a recipient of Hong Kong Scholars Program.
July 2023: Our paper CT-Net: Arbitrary-Shaped Text Detection via Contour Transformer is accepted by IEEE TCSVT.
June 2023: I am a recipient of General Project of China Postdoctoral Science Foundation.
May 2023: Our paper Facial Action Unit Detection via Adaptive Attention and Relation is accepted by IEEE TIP.
Jan. 2023: I am a recipient of Outstanding Young Teacher Program of the China University of Mining and Technology.
Jan. 2023: I serve as a Publication Chair in Computer Graphics International (CGI) 2023.
Dec. 2022: Our paper Facial Action Unit Detection Using Attention and Relation Learning becomes an ESI highly cited paper.
July 2022: I am a recipient of Talent Program for Deputy General Manager of Science and Technology of Jiangsu Province.
June 2022: Our paper TextDCT: Arbitrary-Shaped Text Detection via Discrete Cosine Transform Mask is accepted by IEEE TMM.
Aug. 2021: I am a recipient of Young Scientists Fund of the National Natural Science Foundation of China.
July 2021: I am a recipient of High-Level Talent Program for Innovation and Entrepreneurship (ShuangChuang Doctor) of Jiangsu Province.
June 2021: Our paper Unconstrained Facial Action Unit Detection via Latent Feature Domain is accepted by IEEE TAFFC.
Apr. 2021: Our paper Explicit Facial Expression Transfer via Fine-Grained Representations is accepted by IEEE TIP.
Sept. 2020: I serve as a PC member in AAAI 2021 and IJCAI 2021.
Aug. 2020: Our paper JÂA-Net: Joint Facial Action Unit Detection and Face Alignment via Adaptive Attention is accepted by IJCV.
Oct. 2019: Our paper Facial Action Unit Detection Using Attention and Relation Learning is accepted by IEEE TAFFC.
July 2018: Our paper Deep Adaptive Attention for Joint Facial Action Unit Detection and Face Alignment is accepted by ECCV 2018.
Nov. 2017: I am now studying at Multimedia and Interactive Computing Lab of Nanyang Technological University (NTU), Singapore as a research assistant, advised by Prof. Jianfei Cai.
Timeline
Sponsored Projects
2025: Frontier Technology Research and Development Program of Xuzhou, Principal Investigator
2024: Young Academic Leader Program of the China University of Mining and Technology, Principal Investigator
2024: General Project of the National Natural Science Foundation of China, Principal Investigator
2024: Enterprise Project for Processing and Analysis of Rehabilitation Medicine Data, Principal Investigator
2023: Hong Kong Scholars Program, Principal Investigator
2023: Enterprise Project for Anti-Drowning Safety Management System in Swimming Venue Based on AI and Big Data Analysis, Principal Investigator
2023: Opening Fund of Key Laboratory of Image Processing and Intelligent Control (Huazhong University of Science and Technology), Ministry of Education, Principal Investigator
2023: General Project of China Postdoctoral Science Foundation, Principal Investigator
2023: Outstanding Young Teacher Program of the China University of Mining and Technology, Principal Investigator
2022: Participation in Computer Graphics International (CGI) 2022 Supported by K.C.Wong Education Foundation, Principal Investigator
2022: Patent License Project for Method and Device of Facial Action Unit Recognition Based on Joint Learning and Optical Flow Estimation, Principal Investigator
2022: Talent Program for Deputy General Manager of Science and Technology of Jiangsu Province, Principal Investigator
2021: Young Scientists Fund of the National Natural Science Foundation of China, Principal Investigator
2021: High-Level Talent Program for Innovation and Entrepreneurship (ShuangChuang Doctor) of Jiangsu Province, Principal Investigator
2021: Young Scientists Fund of the Fundamental Research Funds for the Central Universities, Principal Investigator
2020: Start-Up Grant of the China University of Mining and Technology, Principal Investigator
Awards
2026: Top Ten Outstanding Young Faculties of the China University of Mining and Technology
2024: Best Student Paper Award in 2024 CSIG Conference on Emotional Intelligence, Corresponding Author
2024: The 3rd National Youth Skilled Worker in the Coal Industry
2024: First Prize for Technological Achievement of Department of Education of the Henan Province, 2/10
2023: Excellent Thesis Advisor of the China University of Mining and Technology
2022: Honorable Mention for Teaching Competition at the School of Computer Science and Technology, China University of Mining and Technology
2021: Excellent Headteacher of the China University of Mining and Technology
2020: Outstanding Prize for Scientific and Technological Progress of Shanghai Municipality, 11/18
2020: One of the Top 10 Scientific Advances in the Shanghai Jiao Tong University, 8/9
2019: Super AI Leader (SAIL) TOP 30 project at World Artificial Intelligence Conference, 6/13
2016-2019: KoGuan Endeavor Scholarship, Suzhou Yucai Scholarship
2015: Outstanding Graduate of the Northwestern Polytechnical University
2012-2015: Outstanding Student of the Northwestern Polytechnical University
2012-2015: National Endeavor Scholarship, Samsung China Scholarship, Wu Yajun Scholarship
Selected Publications
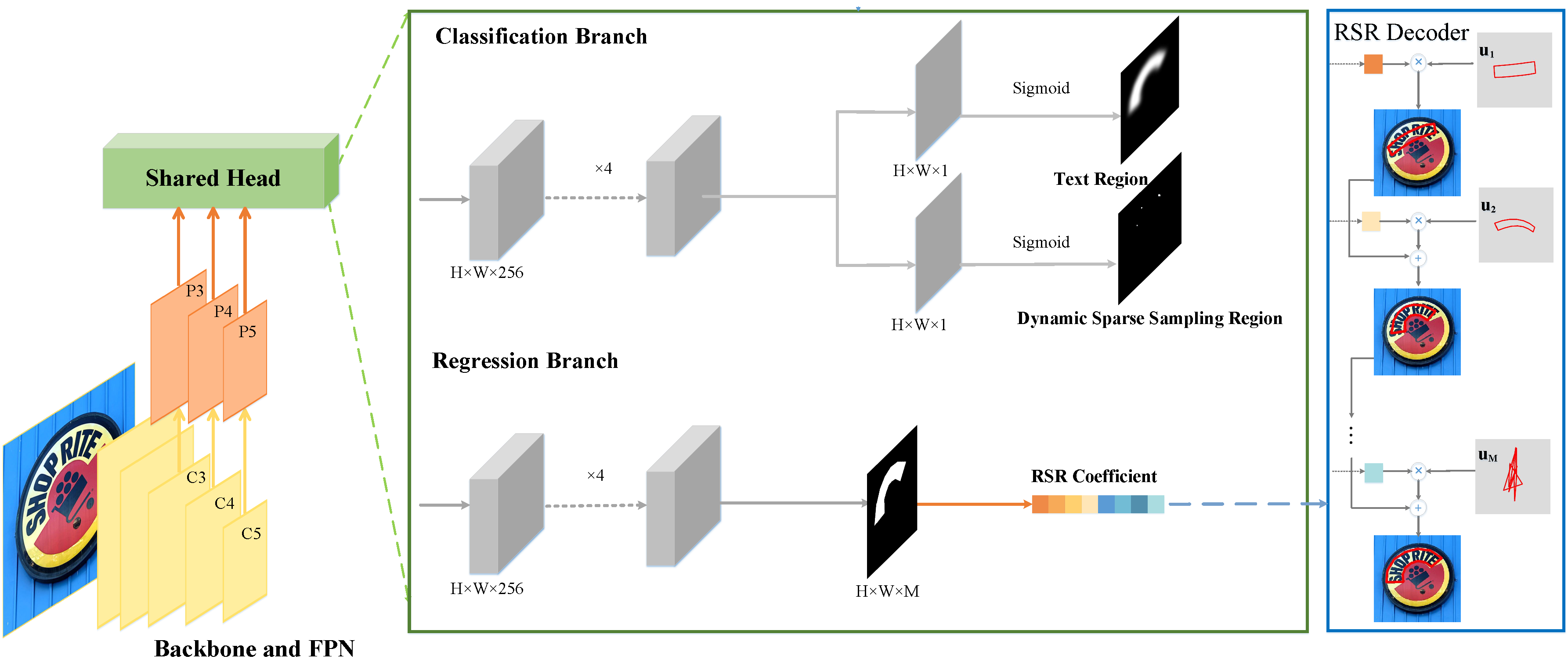
We first propose a novel text representation method based on robust subspace recovery, which robustly represents complex text shapes by combining orthogonal basis vectors learned from labeled text contours. These basis vectors capture basis contour patterns with distinct information, enabling clearer boundaries even in densely populated text scenarios. Moreover, we propose a dynamic sparse assignment scheme for positive samples that adaptively adjusts their weights during training, which not only accelerates inference speed by eliminating redundant predictions but also enhances feature learning by providing sufficient supervision signals. Building on these innovations, we present TextRSR, an accurate and efficient scene text detection network.
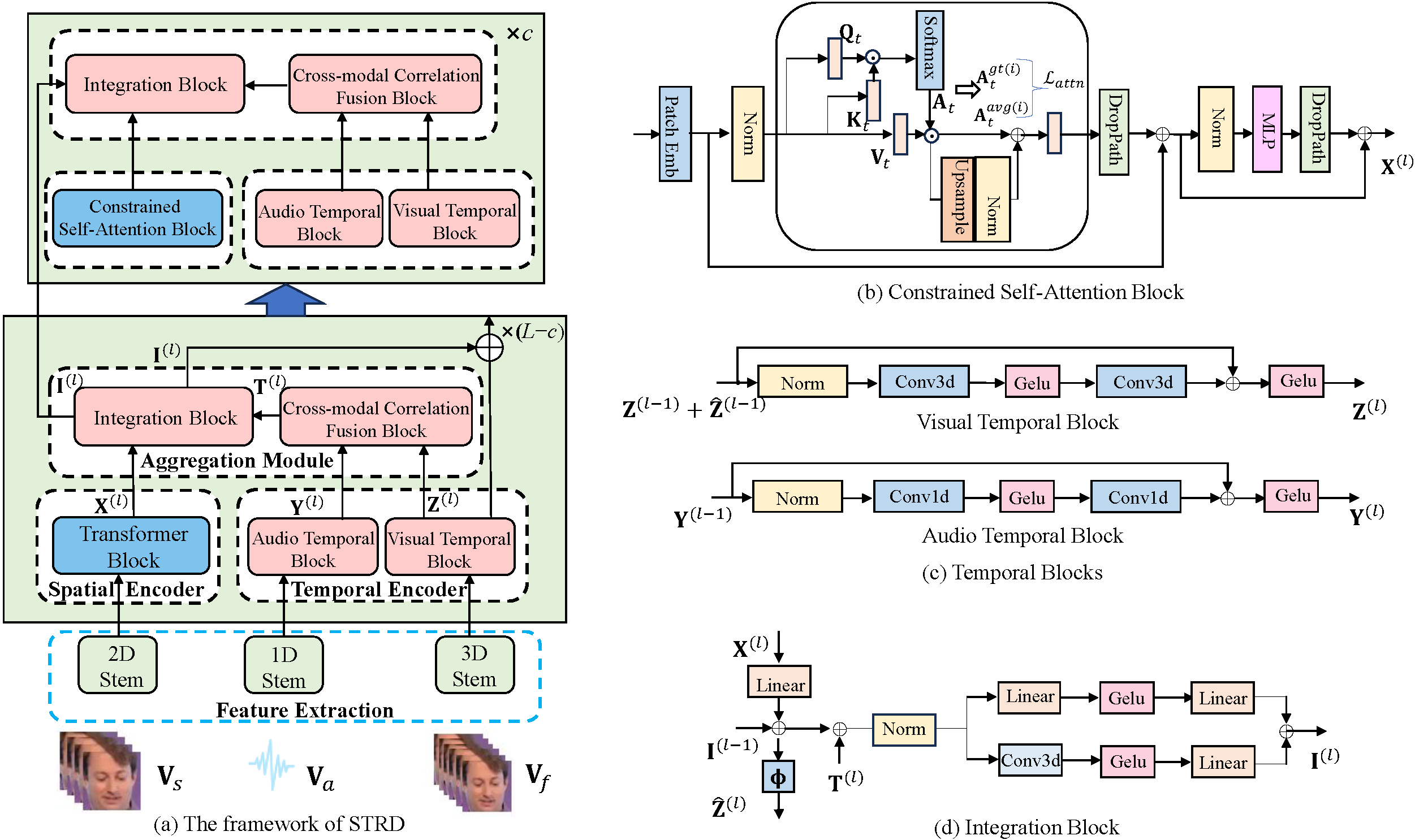
We propose a Spatio-Temporal Representation Disentanglement (STRD) framework for multi-modal deception detection, which uses a dual-encoder structure to learn spatial and temporal representations for each modality. Specifically, we introduce a pre-trained foundation model to act as the spatial encoder and design a lightweight network as the temporal encoder, extracting spatial semantics and capturing dynamic temporal patterns. Then, we propose a Constrained Self-Attention Block (CSAB), in which self-attention distribution of each head is regarded as spatial distribution and is constrained to attend a certain facial local region. Furthermore, we present a Cross-modal Correlation Fusion Block (CCFB) to achieve temporal synchronization across modalities by measuring the correlations between visual and audio features.
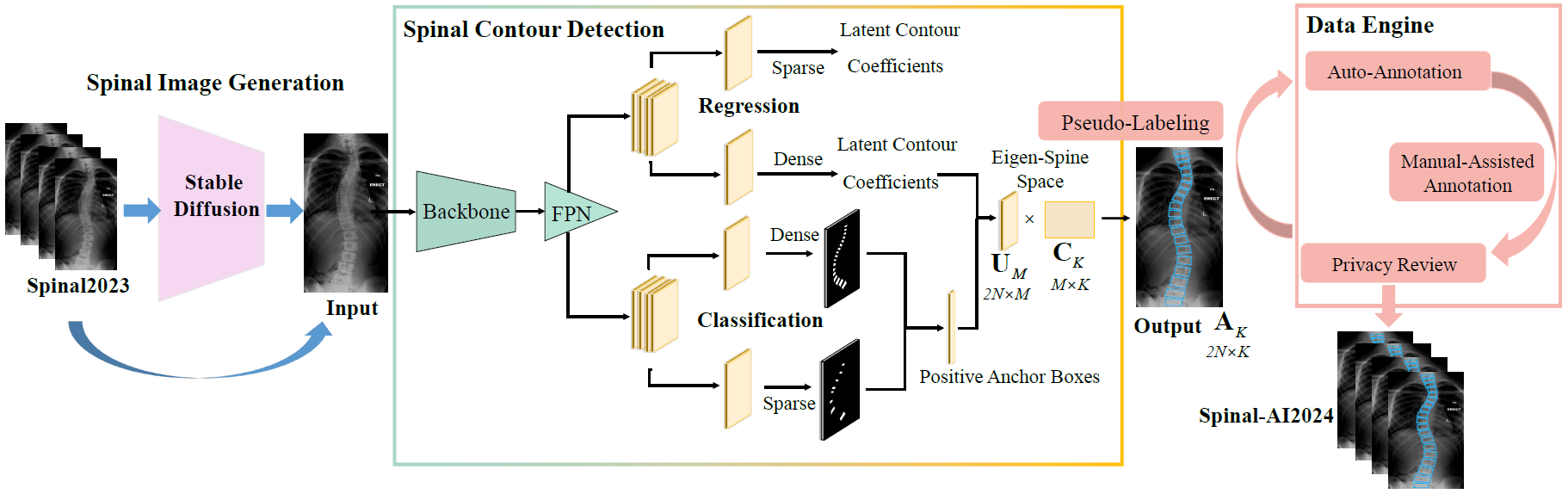
We propose a novel curvature angle estimation framework named CurvNet including latent contour representation based contour detection and iterative data engine based image self-generation. Specifically, we propose a parameterized spine contour representation in latent space, which enables eigen-spine decomposition and spine contour reconstruction. Latent contour coefficient regression is combined with anchor box classification to solve inaccurate predictions and mask connectivity issues. Moreover, we develop a data engine with image self-generation, automatic annotation, and automatic selection in an iterative manner. By our data engine, we generate a clean dataset named Spinal-AI2024 without privacy leaks, which is the largest released scoliosis X-ray dataset to our knowledge.
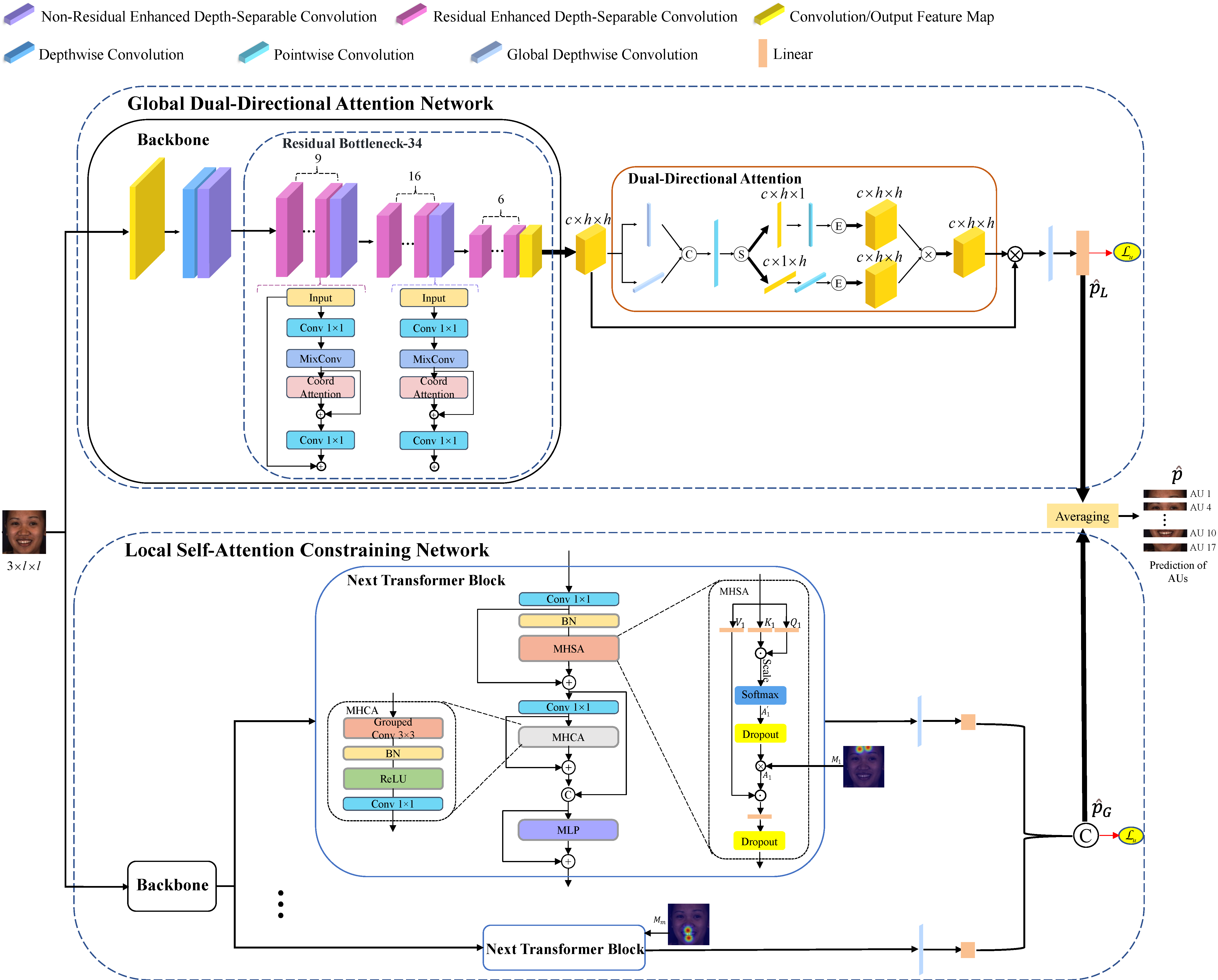
We propose a local self-attention constraining (LSC) network, by regarding the self-attention distribution of each AU as a spatial distribution, and constraining it based on prior knowledge so as to capture AU-related local information. Moreover, to learn correlations among different AU regions, we propose a global dual-directional attention (GDA) network, which adaptively learns global attention map from both vertical and horizontal directions. Last but not least, the two networks from different views of capturing patterns are assembled to integrate both advantages.

We propose an efficient, scene-aware multi-object arrangement method (MOA) designed for fast, precise, and convenient object arrangement. First, MOA introduces an importance-driven multi-object initial selection algorithm that assigns higher spatiotemporally correlated object importance (IMP) to target objects, establishing a natural multi-object initial selection mode that enables quick and accurate selection of high-IMP objects. Subsequently, it presents an auxiliary-structure-guided multi-object manipulation algorithm that constructs an auxiliary manipulation structure to assist subsequent multi-object manipulation, alongside a multi-modal interaction mode that facilitates swift and natural manipulation.
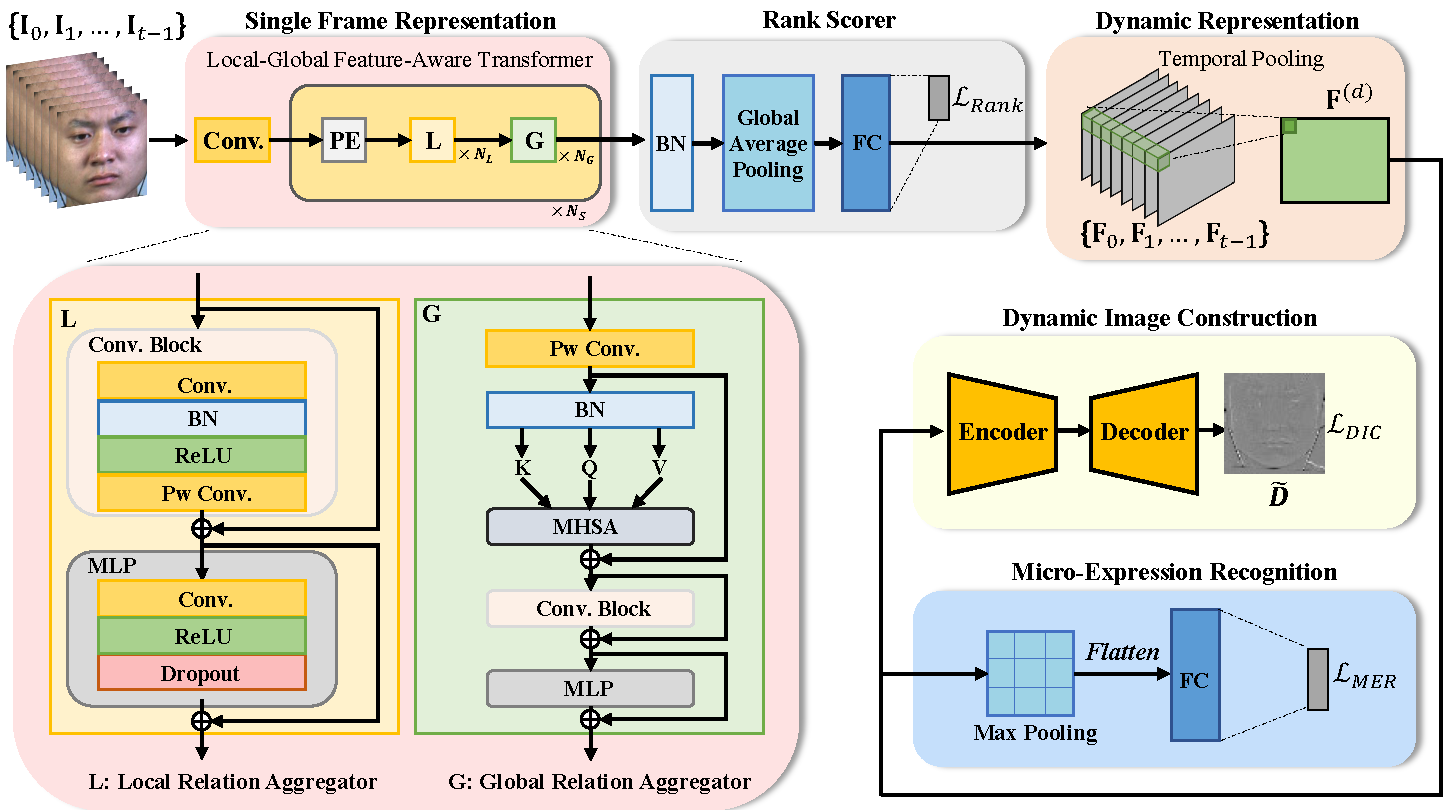
We develop a novel fine-grained dynamic perception (FDP) framework for MER. We propose to rank frame-level features of a sequence of raw frames in chronological order, in which the rank process encodes the dynamic information of both ME appearances and motions. Specifically, a novel local-global feature-aware transformer is proposed for frame representation learning. A rank scorer is further adopted to calculate rank scores of each frame-level feature. Afterwards, the rank features from rank scorer are pooled in temporal dimension to capture dynamic representation. Finally, the dynamic representation is shared by a MER module and a dynamic image construction module, in which the former predicts the ME category, and the latter uses an encoder-decoder structure to construct the dynamic image. The design of dynamic image construction task is beneficial for capturing facial subtle actions associated with MEs and alleviating the data scarcity issue.
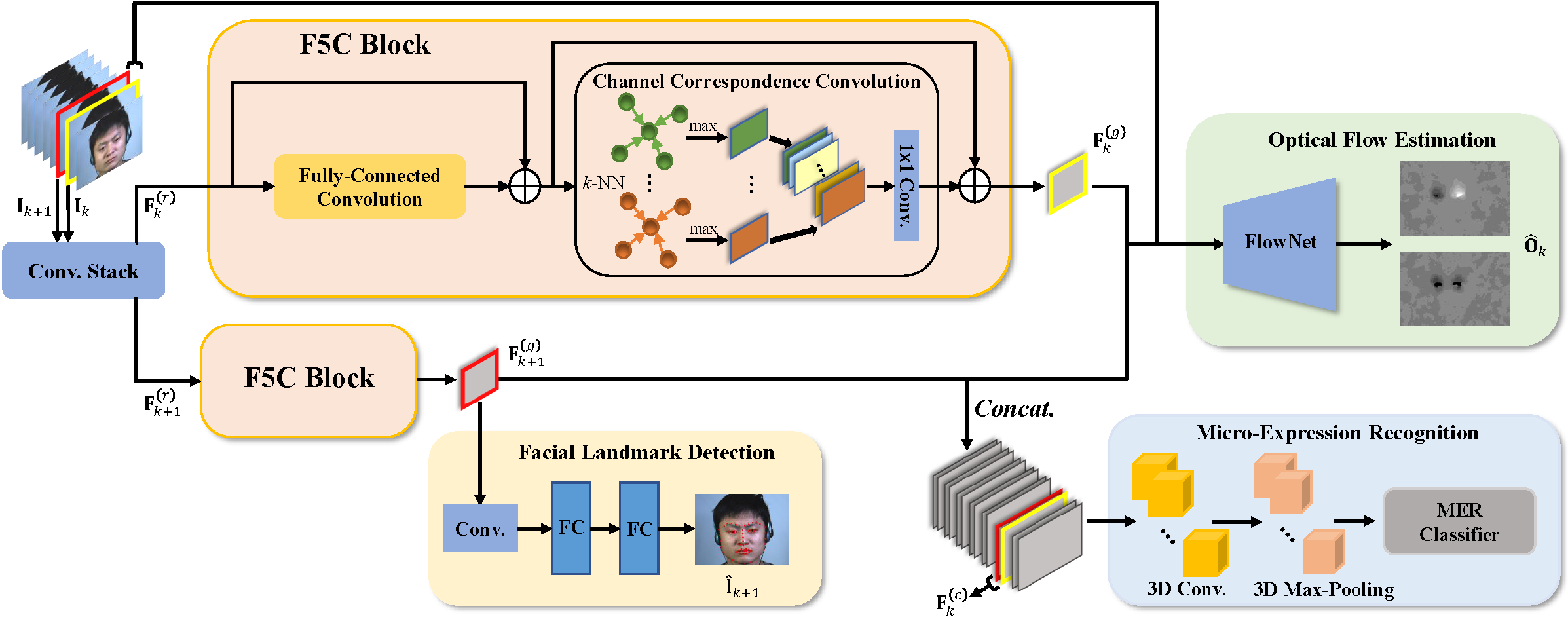
We propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data.
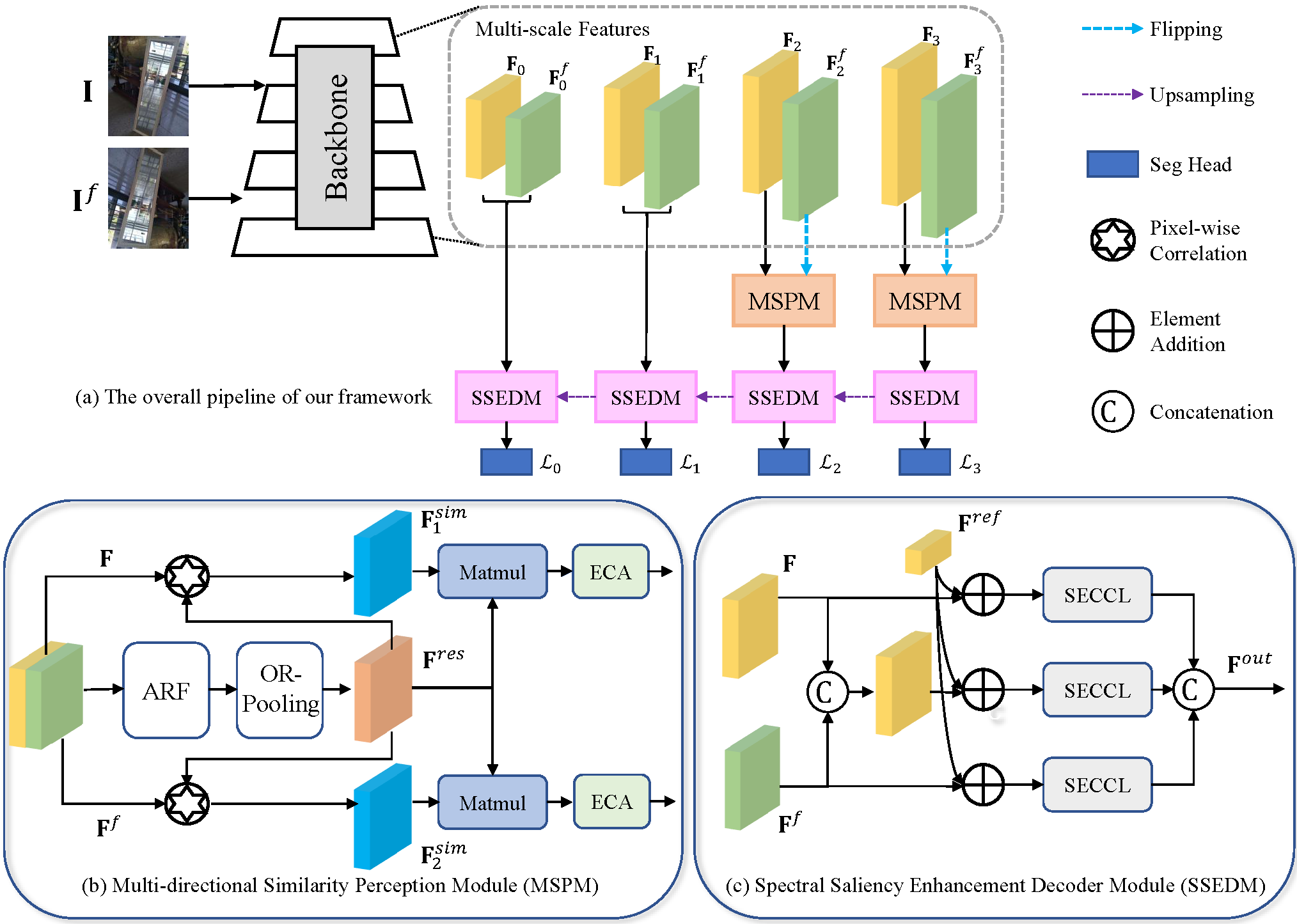
We propose a novel mirror detection framework called S2MD including two main modules, multi-directional similarity perception module (MSPM) and spectral saliency enhancement decoder module (SSEDM). Specifically, we employ a backbone network to extract multi-scale global information from images using a dual-path approach. Then, we feed these high-level dual-path features into MSPMs to generate direction-sensitive similarity-consistent features. MSPM utilizes active rotating filters and oriented response pooling to model the similarity relations in different orientations. Moreover, the SSEDM is utilized to enhance the spatial contextual contrasted features using feature spectral residuals and fuse the dual-path features to obtain the final predicted mirror mask.
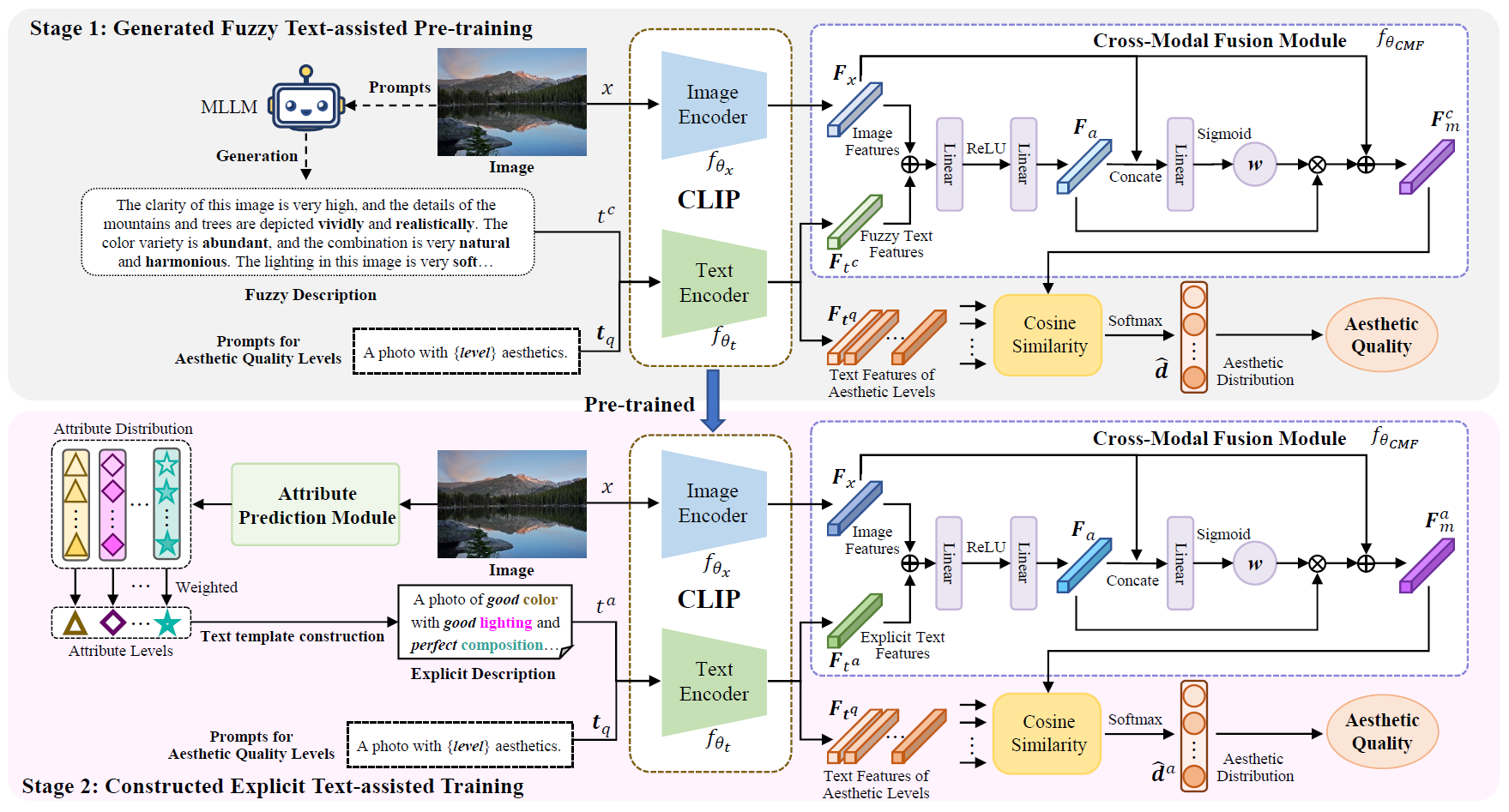
This paper proposes a progressively generated text-assisted image aesthetic quality assessment method, aiming to address the lack of aesthetic comments and the fuzziness of aesthetic judgments in these comments. Specifically, we first adopt a Multimodal Large Language Model (MLLM) to generate aesthetic comments on images by simulating user perceptions and utilize the generated comments to characterize their aesthetic perception to assist in the pretraining of our multimodal-based IAQA model. Then, we design an attribute prediction module to determine the attribute levels of aesthetic judgments and utilize text template construction to further generate explicit descriptions of image aesthetics. Finally, we leverage the generated attribute descriptions to further assist in training our IAQA model. By progressively generating textual auxiliary descriptions of aesthetics for images, the proposed model can gradually determine the aesthetic quality of the images.
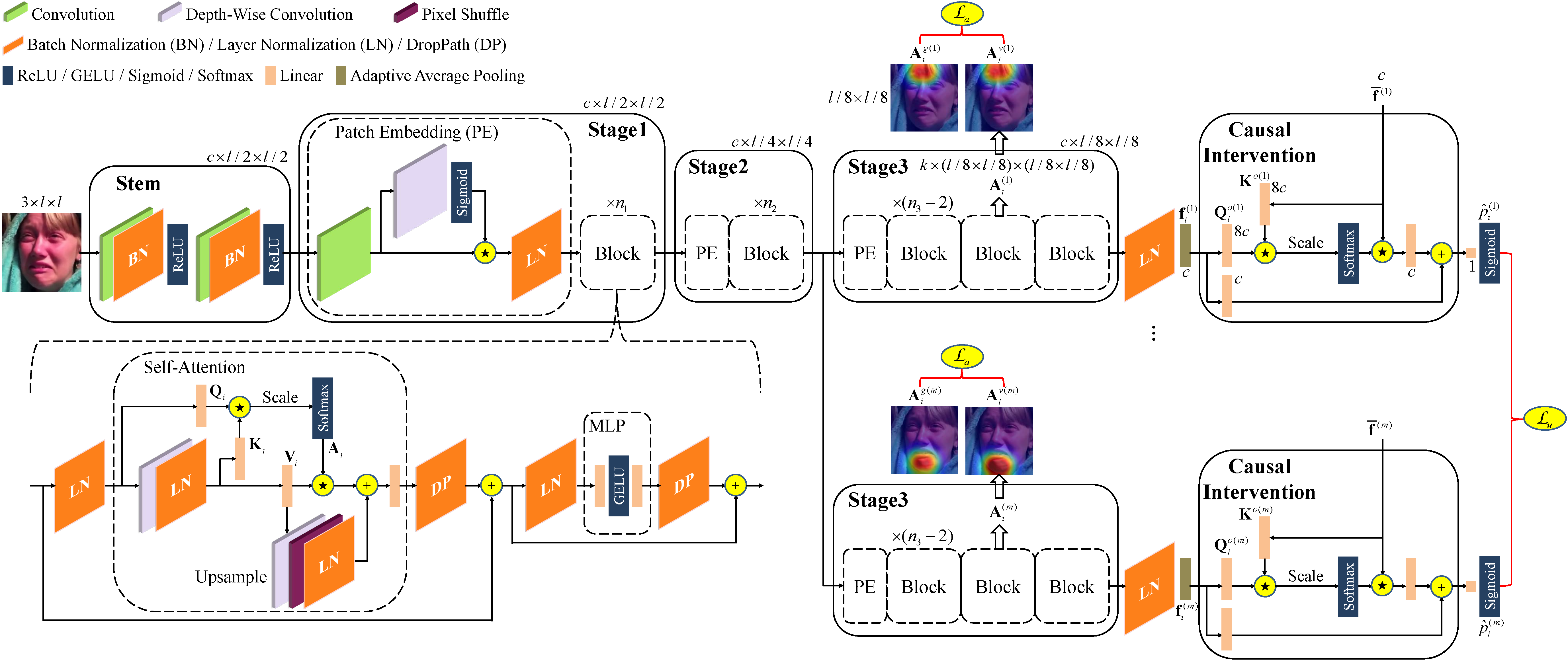
We propose a novel AU detection framework called AC2D by adaptively constraining self-attention weight distribution and causally deconfounding the sample confounder. Specifically, we explore the mechanism of self-attention weight distribution, in which the self-attention weight distribution of each AU is regarded as spatial distribution and is adaptively learned under the constraint of location-predefined attention and the guidance of AU detection. Moreover, we propose a causal intervention module for each AU, in which the bias caused by training samples and the interference from irrelevant AUs are both suppressed.
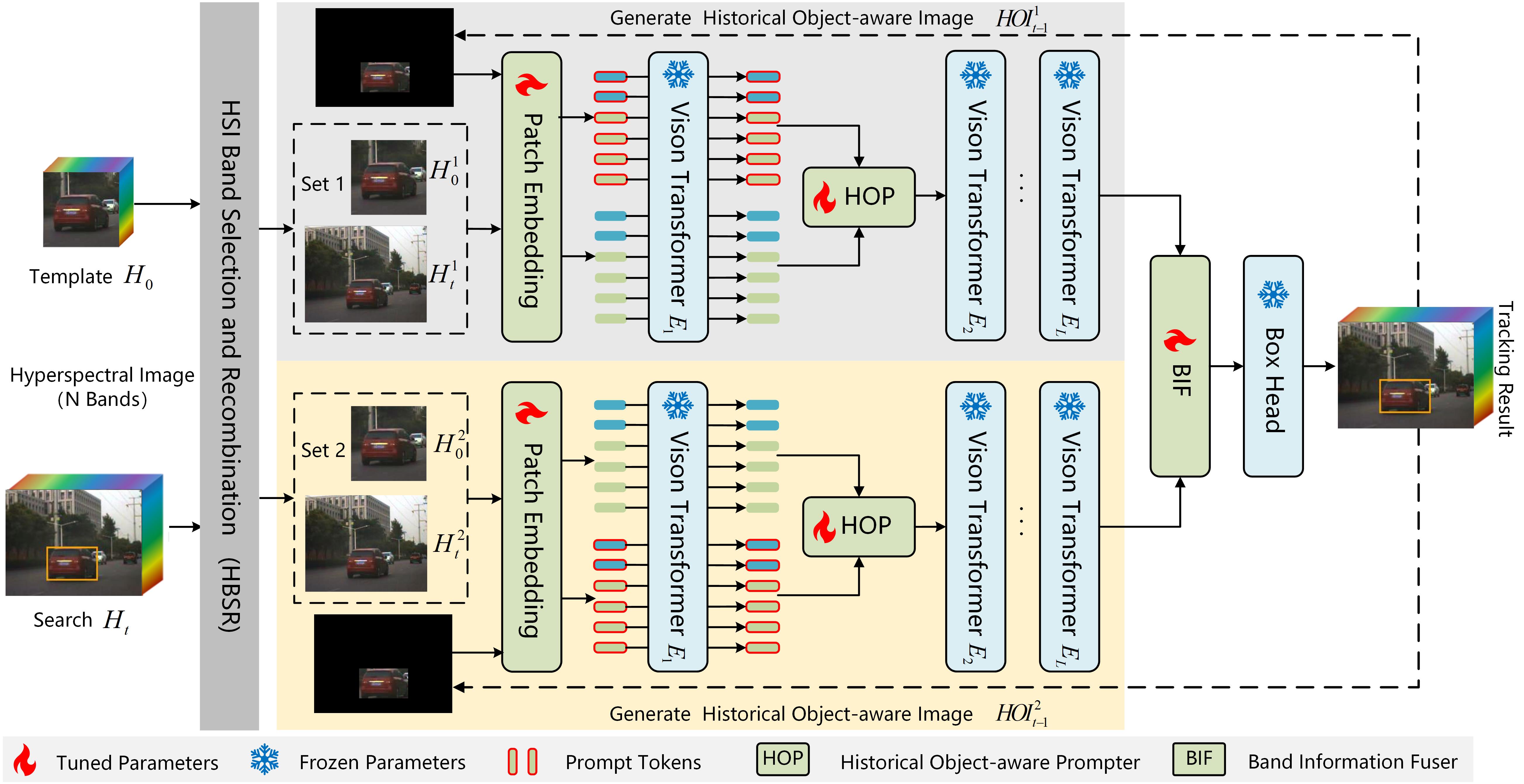
We propose a Historical Object-aware Prompt Learning (HOPL) method for universal hyperspectral object tracking. Initially, we transform hyperspectral image (N bands) into multiple sets of 3 bands with different combinations and feed them into a backbone network to generate base features. Subsequently, we introduce a historical object-aware prompter, where historical object-aware images are input to generate prompt features that enhance the representation of object information when combined with base features. Additionally, we design a band information fusion module to integrate the multiple sets of base features. By introducing historical object-aware prompts, HOPL significantly enhances tracking performance without retraining the backbone network.
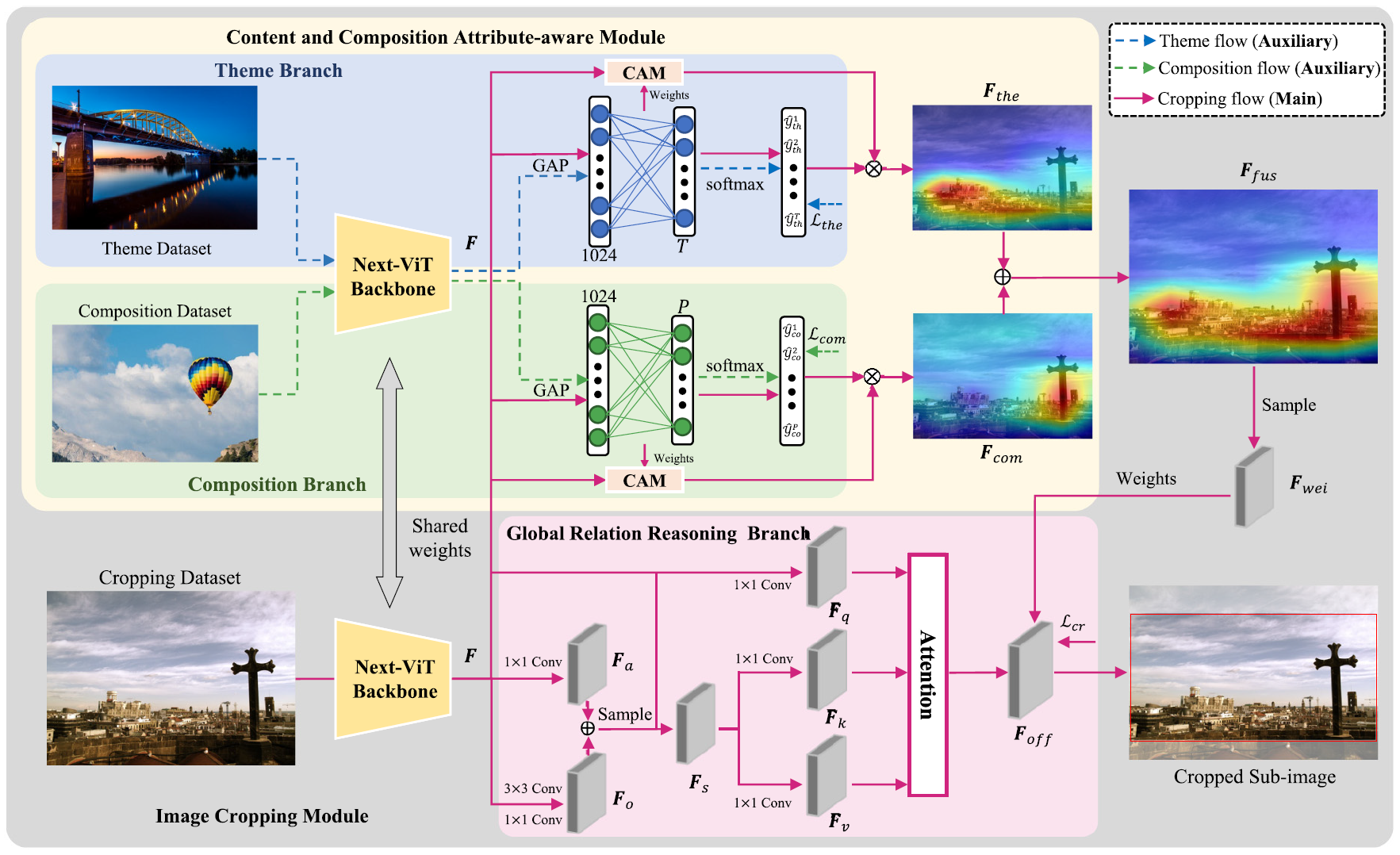
To comprehensively introduce aesthetic information into image cropping, we capture feature representations reinforced by content and composition attributes simultaneously. The feature representations can strengthen the visual aesthetics of cropped sub-images. To make the cropped sub-images amply contain more global information, we introduce a global relation reasoning branch in the proposed cropping module, which can fully exploit the dependency relationship between the foreground and background in images.

This paper redefines online time series forecasting to focus on predicting unknown future steps and evaluates performance solely based on these predictions. Following this new setting, challenges arise in leveraging incomplete pairs of ground truth and prediction for backpropagation, as well as generalizing accurate information without overfitting to noises from recent data streams. To address these challenges, we propose a novel dual-stream framework for online forecasting (DSOF): a slow stream that updates with complete data using experience replay, and a fast stream that adapts to recent data through temporal difference learning. This dual-stream approach updates a teacher-student model learned through a residual learning strategy, generating predictions in a coarse-to-fine manner.

We introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR).
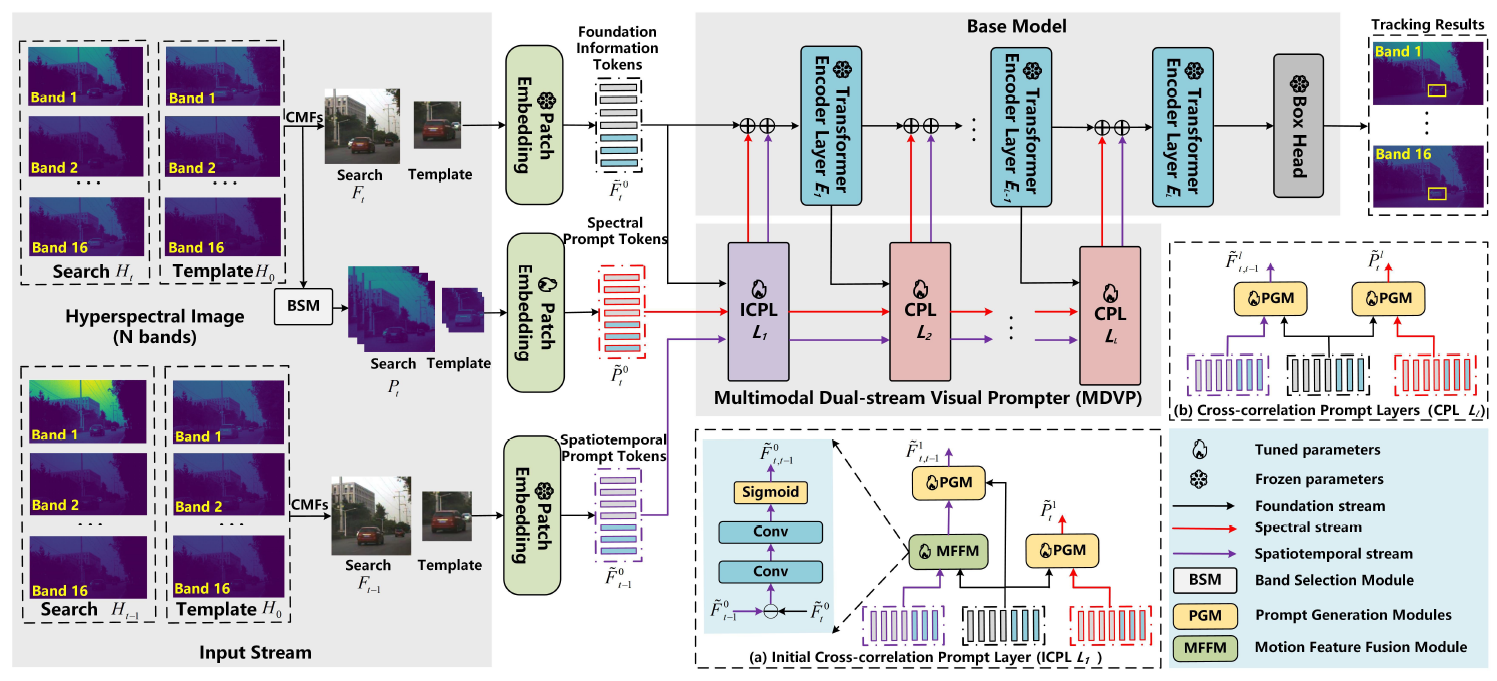
We propose a unified spectral-spatiotemporal multimodal dual-stream prompt hyperspectral object tracking, named HDSP. We design a density clustering-based band selection module to preserve spectral prompt information efficiently. Using the generated bands and temporal data as multimodal prompts, a dual-stream visual prompter is proposed. Designed Multimodal Dual-stream Visual Prompter (MDVP) transform the multimodal input into a single modality, enhancing the foundational modality’s representation capabilities for hyperspectral tracking.
This paper proposes an image enhancement method based on content-aware multimodal fusion, which supplements image features by incorporating text features that describe the semantic perception of image content. By fusing features from both image and text modalities, the proposed approach captures multimodal content-aware semantics, enabling fine-grained adjustments tailored to different image content. Firstly, a multimodal large language model is employed to extract textual descriptions of image content, which are then used for multimodal prompt learning to guide the understanding of the image content. This method enables the model to leverage content-based text prompts for auxiliary image enhancement. Then, an attention mechanism is then applied to effectively integrate and fuse the textual and image features into a unified multimodal representation. Finally, this representation is used to construct a curve-mapping function, enabling content-specific image adjustments and enhancements.
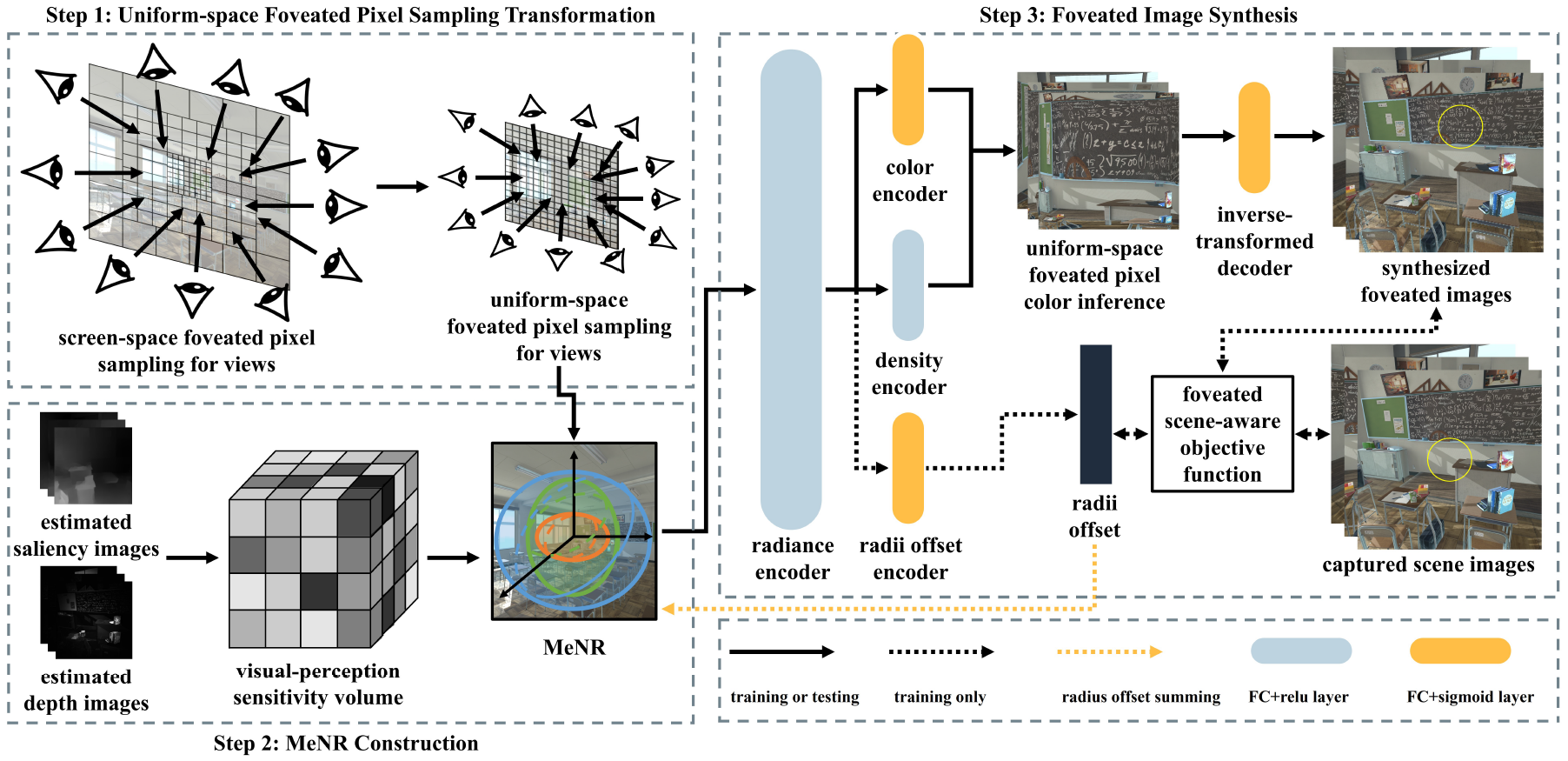
We propose a scene-aware foveated neural radiance fields method to synthesize high-quality foveated images in complex VR scenes at high frame rates. Firstly, we construct a multi-ellipsoidal neural representation to enhance the neural radiance fields representation capability in salient regions of complex VR scenes based on the scene content. Then, we introduce a uniform sampling based foveated neural radiance fields framework to improve the foveated image synthesis performance with one-pass color inference, and improve the synthesis quality by leveraging the foveated scene-aware objective function.
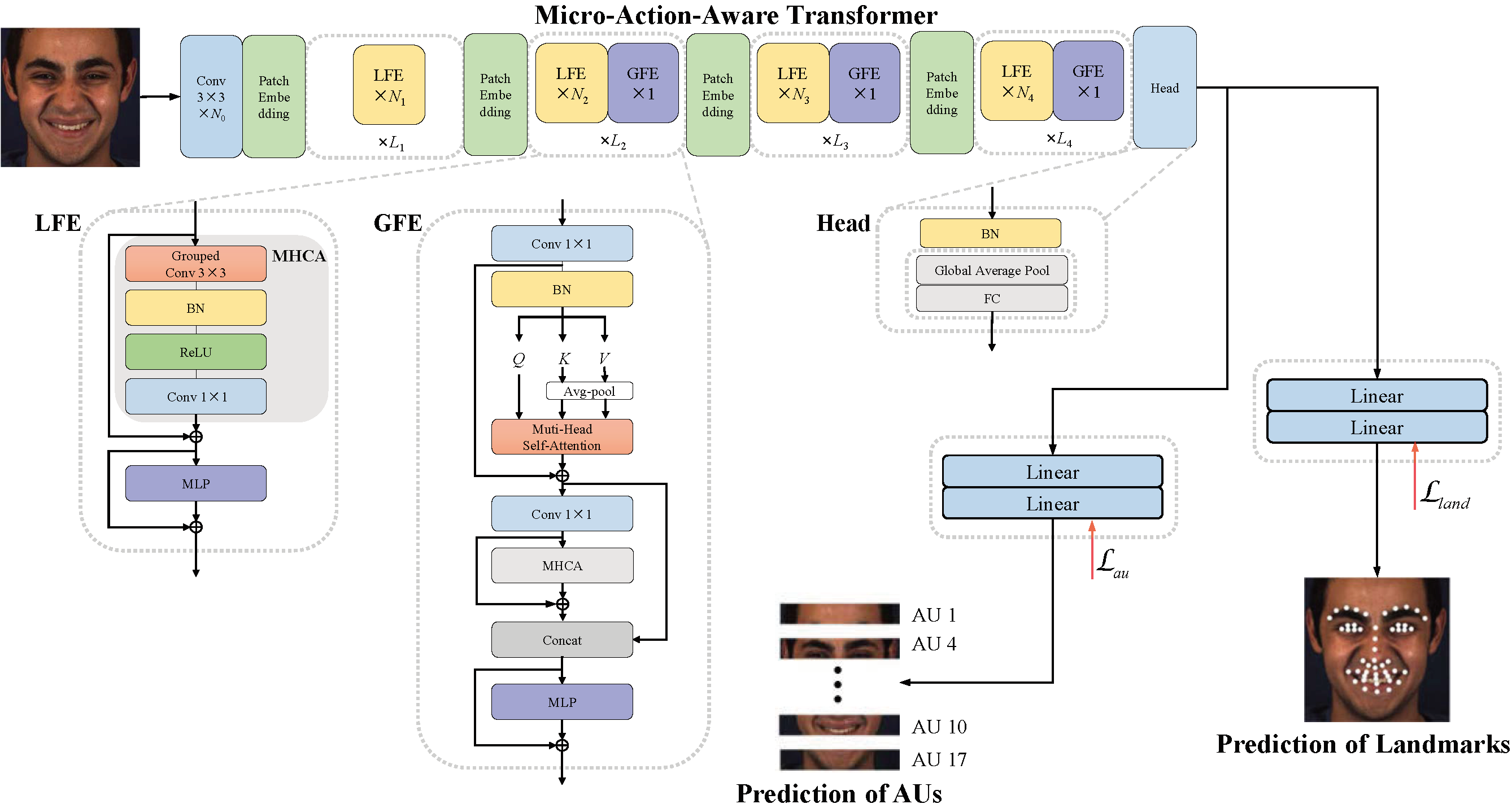
We propose a novel micro-action-aware transformer to integrate local and global feature extractions, which effectively captures subtle AU details while maintaining the global relational modeling capacity of transformers. Besides, we jointly train facial AU recognition and facial landmark detection, in which the two correlated tasks contribute to each other and further facilitate the learning of local-global AU-related feature.
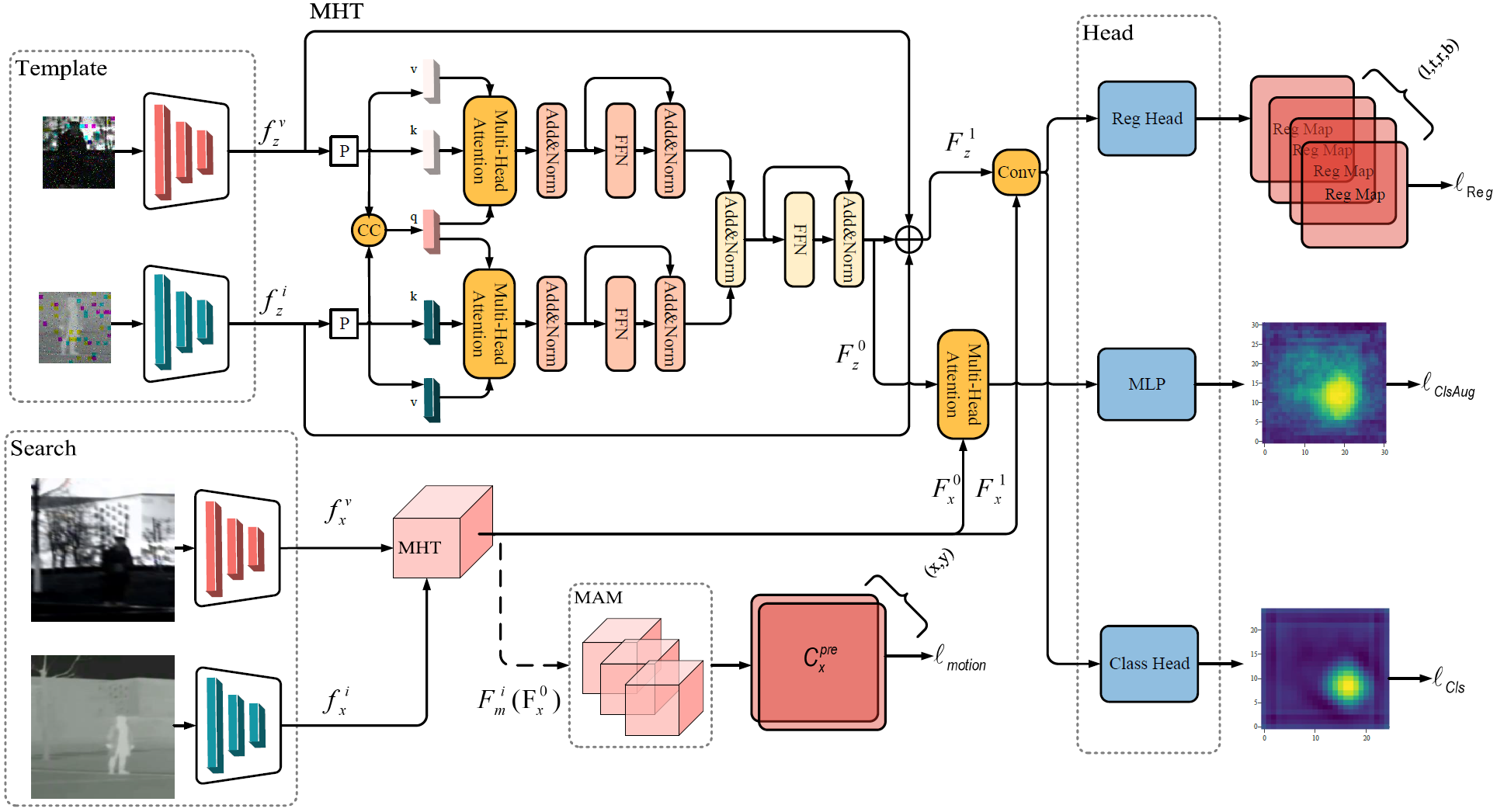
We propose a self-supervised RGBT object tracking method (S2OTFormer) to bridge the gap between tracking methods supervised under pseudo-labels and ground truth labels. Firstly, to provide more robust appearance features for motion cues, we introduce a Multi-Modal Hierarchical Transformer module (MHT) for feature fusion. This module allocates weights to both modalities and strengthens the expressive capability of the MHT module through multiple nonlinear layers to fully utilize the complementary information of the two modalities. Secondly, in order to solve the problems of motion blur caused by camera motion and inaccurate appearance information caused by pseudo-labels, we introduce a Motion-Aware Mechanism (MAM). The MAM extracts the average motion vectors from the previous multi-frame search frame features and constructs the consistency loss with the motion vectors of the current search frame features. The motion vectors of inter-frame objects are obtained by reusing the inter-frame attention map to predict coordinate positions. Finally, to further reduce the effect of inaccurate pseudo-labels, we propose an Attention-Based Multi-Scale Enhancement Module. By introducing cross-attention to achieve more precise and accurate object tracking, this module overcomes the receptive field limitations of traditional CNN tracking heads.
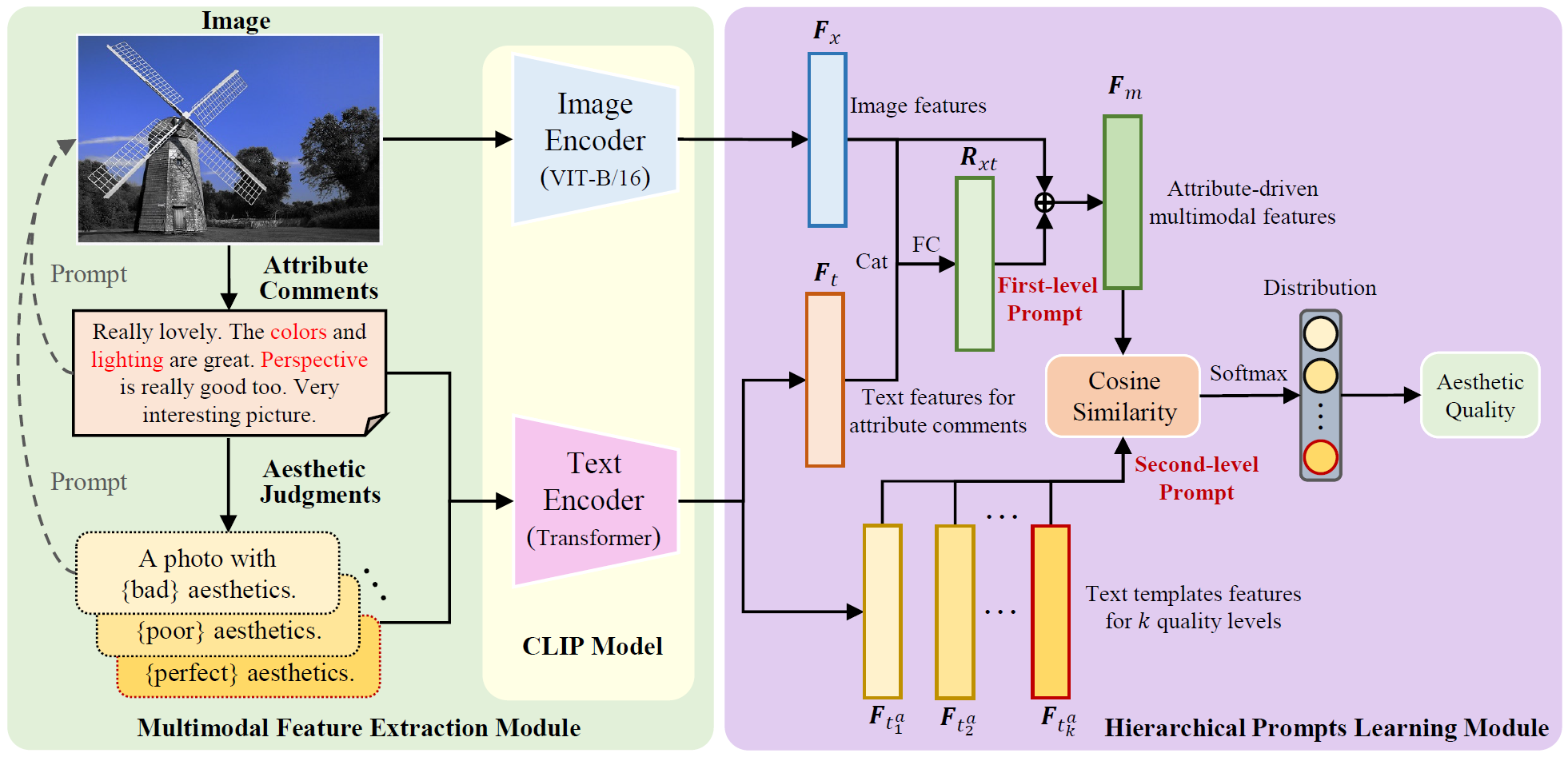
This paper proposes an image aesthetic quality assessment method based on attribute-driven multimodal hierarchical prompts. Unlike existing IAQA methods that utilize multimodal pre-training or straightforward prompts for model learning, the proposed method leverages attribute comments and quality-level text templates to hierarchically learn the aesthetic attributes and quality of images. Specifically, we first leverage aesthetic attribute comments to perform prompt learning on images. The learned attribute-driven multimodal features can comprehensively capture the semantic information of image aesthetic attributes perceived by users. Then, we construct text templates for different aesthetic quality levels to further facilitate prompt learning through semantic information related to the aesthetic quality of images. The proposed method can explicitly simulate aesthetic judgment of images to obtain more precise aesthetic quality.

By introducing causal inference theory, we propose an unbiased AU recognition method CIU (Causal Intervention for Unbiased facial action unit recognition), which adjusts the empirical risks in both the imbalanced and balanced but invisible domains to achieve model unbiasedness.
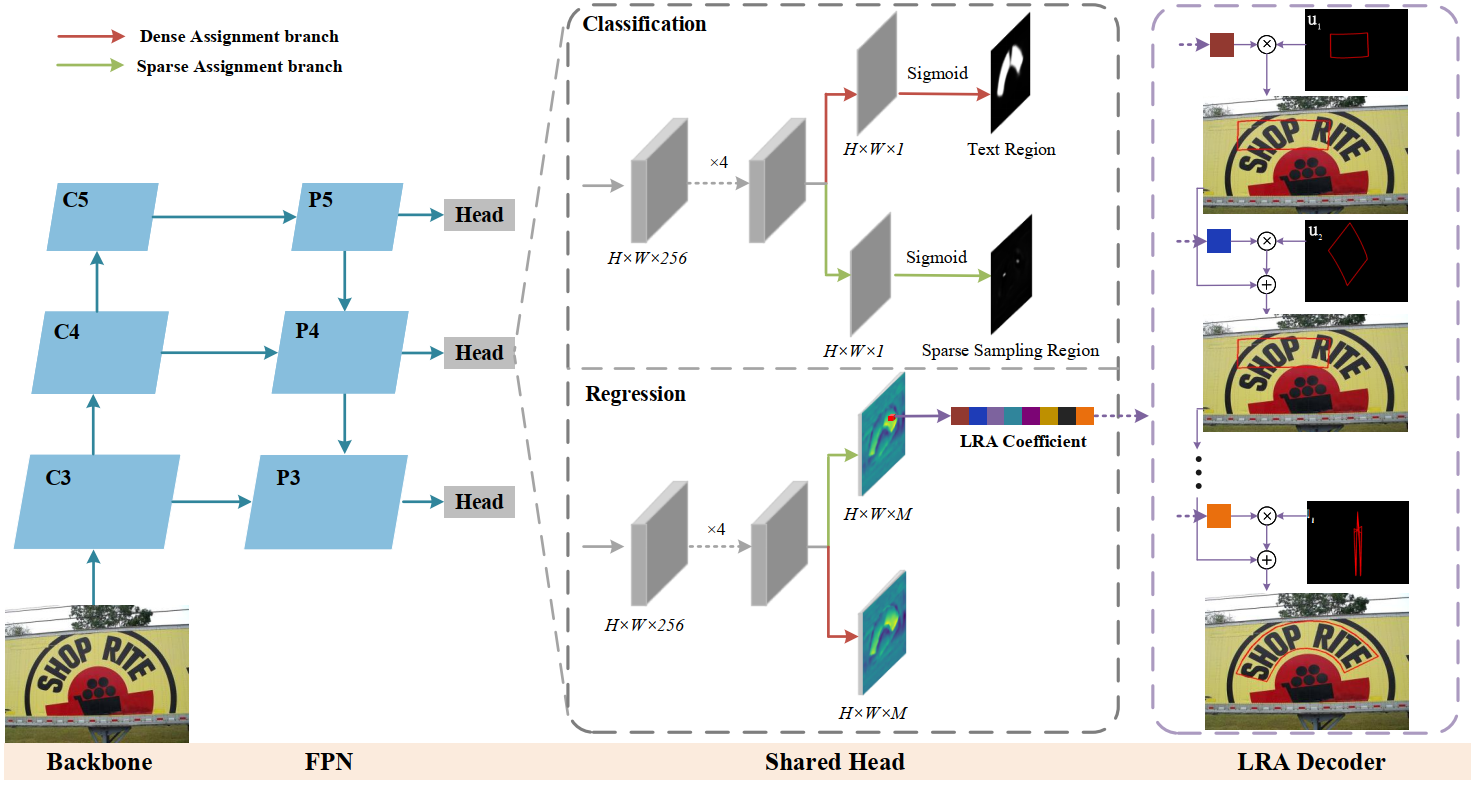
We first propose a novel parameterized text shape method based on low-rank approximation. Unlike other shape representation methods that employ data-irrelevant parameterization, our approach utilizes singular value decomposition and reconstructs the text shape using a few eigenvectors learned from labeled text contours. By exploring the shape correlation among different text contours, our method achieves consistency, compactness, simplicity, and robustness in shape representation. Next, we propose a dual assignment scheme for speed acceleration. It adopts a sparse assignment branch to accelerate the inference speed, and meanwhile, provides ample supervised signals for training through a dense assignment branch. Building upon these designs, we implement an accurate and efficient arbitrary-shaped text detector named LRANet.
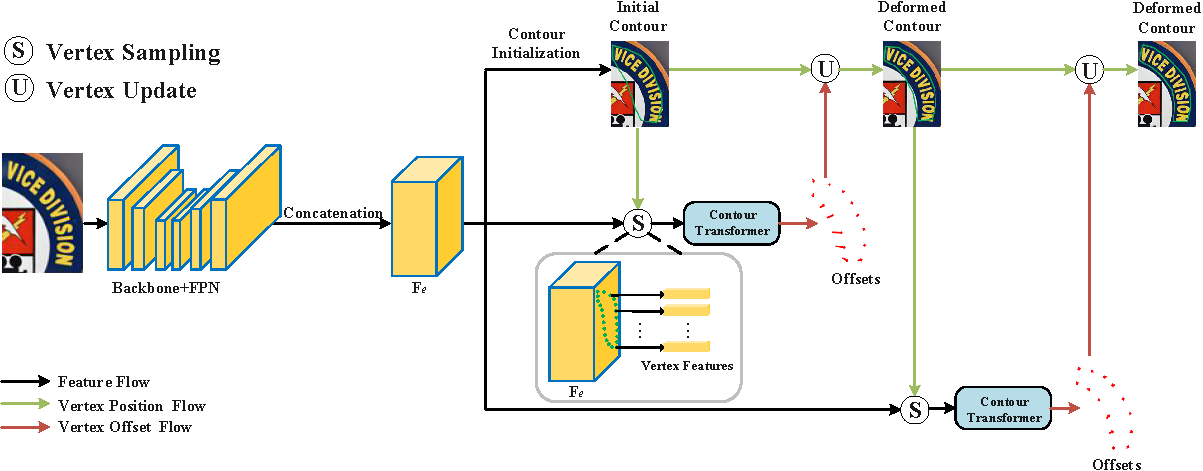
We propose a novel arbitrary-shaped scene text detection framework named CT-Net by progressive contour regression with contour transformers. Specifically, we first employ a contour initialization module that generates coarse text contours without any post-processing. Then, we adopt contour refinement modules to adaptively refine text contours in an iterative manner, which are beneficial for context information capturing and progressive global contour deformation. Besides, we propose an adaptive training strategy to enable the contour transformers to learn more potential deformation paths, and introduce a re-score mechanism that can effectively suppress false positives.
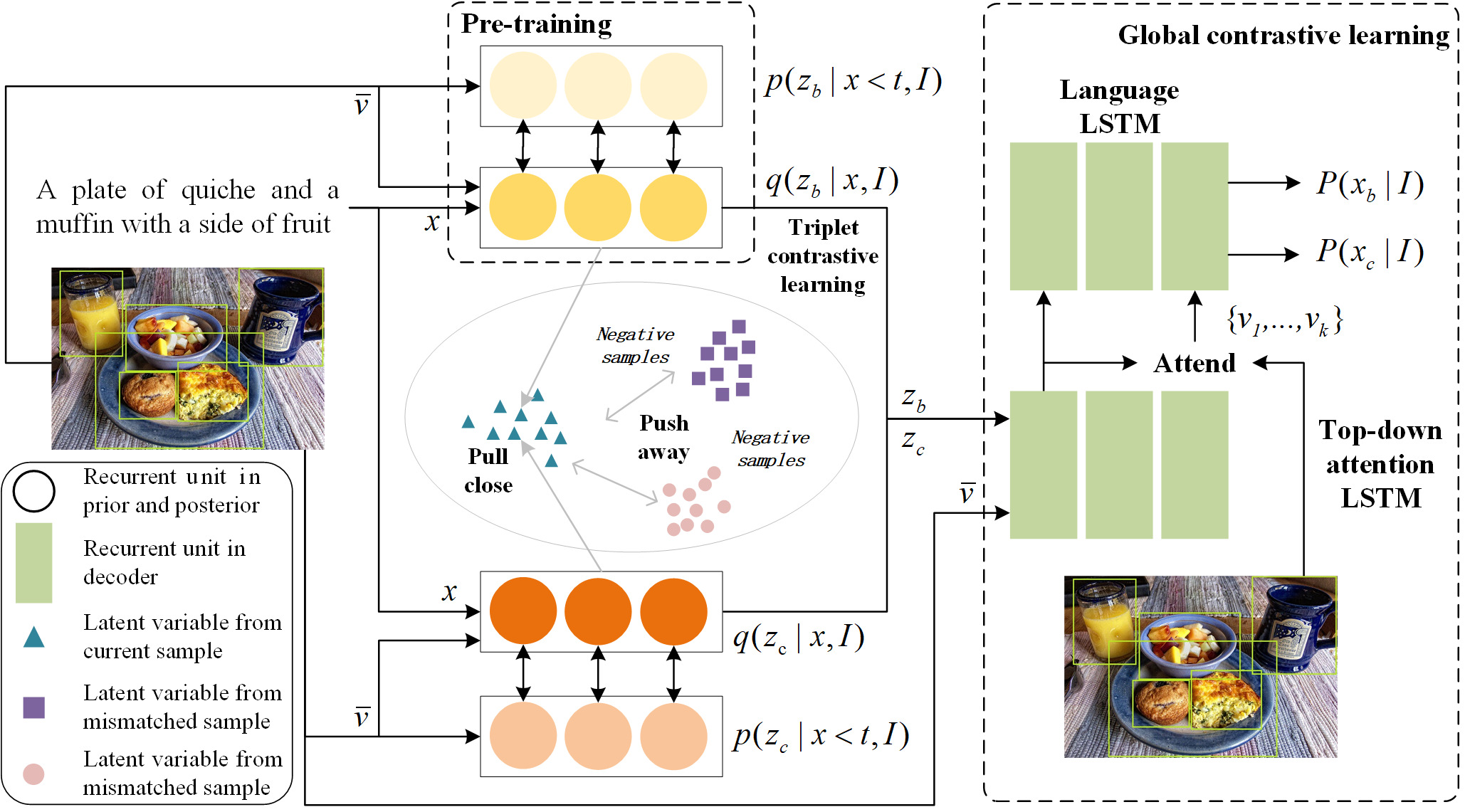
We propose a novel Conditional Variational Autoencoder (DCL-CVAE) framework for diverse image captioning by seamlessly integrating sequential variational autoencoder with contrastive learning. In the encoding stage, we first build conditional variational autoencoders to separately learn the sequential latent spaces for a pair of captions. Then, we introduce contrastive learning in the sequential latent spaces to enhance the discriminability of latent representations for both image-caption pairs and mismatched pairs. In the decoding stage, we leverage the captions sampled from the pre-trained Long Short-Term Memory (LSTM), LSTM decoder as the negative examples and perform contrastive learning with the greedily sampled positive examples, which can restrain the generation of common words and phrases induced by the cross entropy loss. By virtue of dual constrastive learning, DCL-CVAE is capable of encouraging the discriminability and facilitating the diversity, while promoting the accuracy of the generated captions.
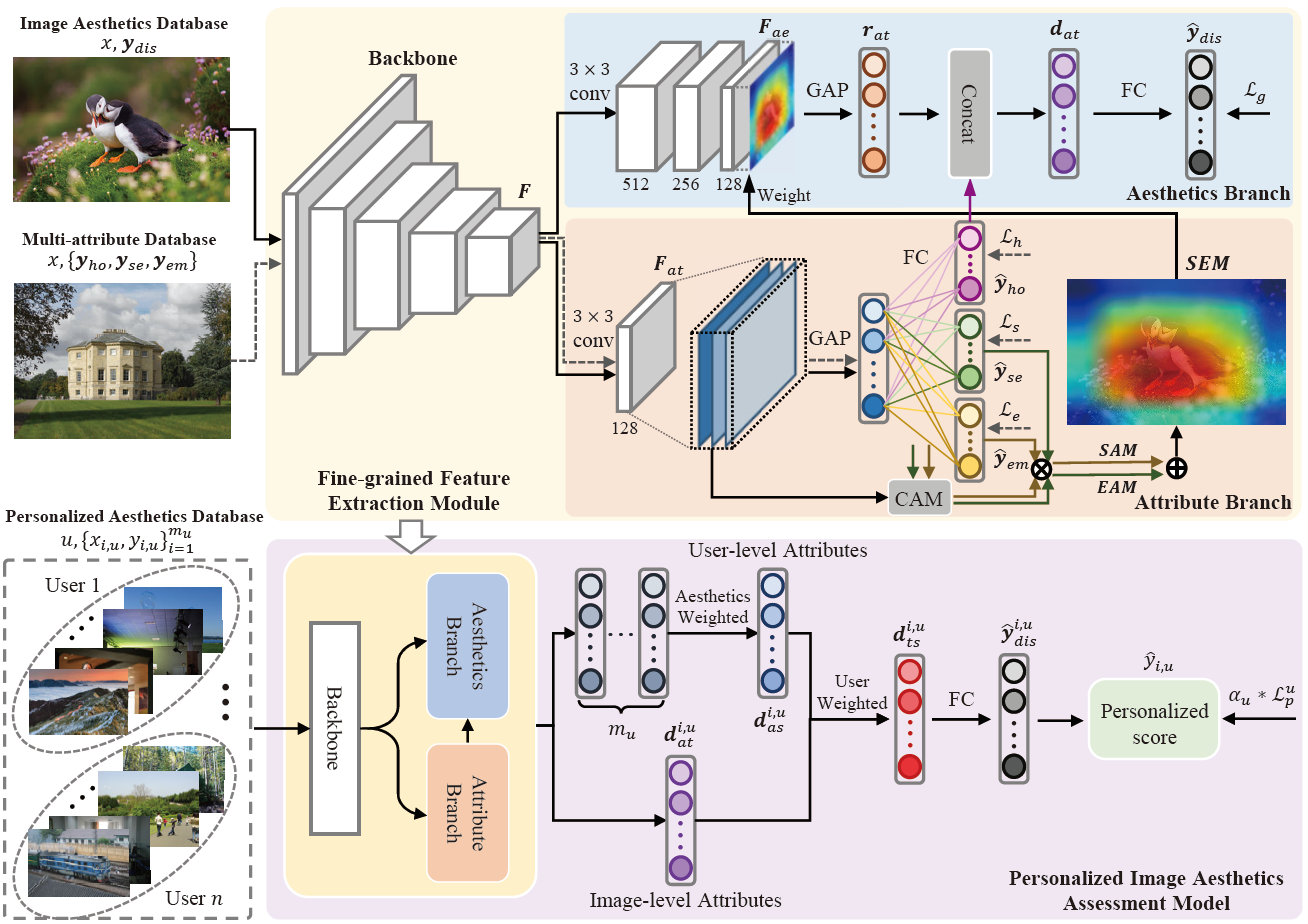
We first build a fine-grained feature extraction (FFE) module to obtain the refined local features of image attributes to compensate for holistic features. The FFE module is then used to generate user-level features, which are combined with the image-level features to obtain user-preferred fine-grained feature representations. By training extensive PIAA tasks, the aesthetic distribution of most users can be transferred to the personalized scores of individual users. To enable our proposed model to learn more generalizable aesthetics among individual users, we incorporate the degree of dispersion between personalized scores and image aesthetic distribution as a coefficient in the loss function during model training.
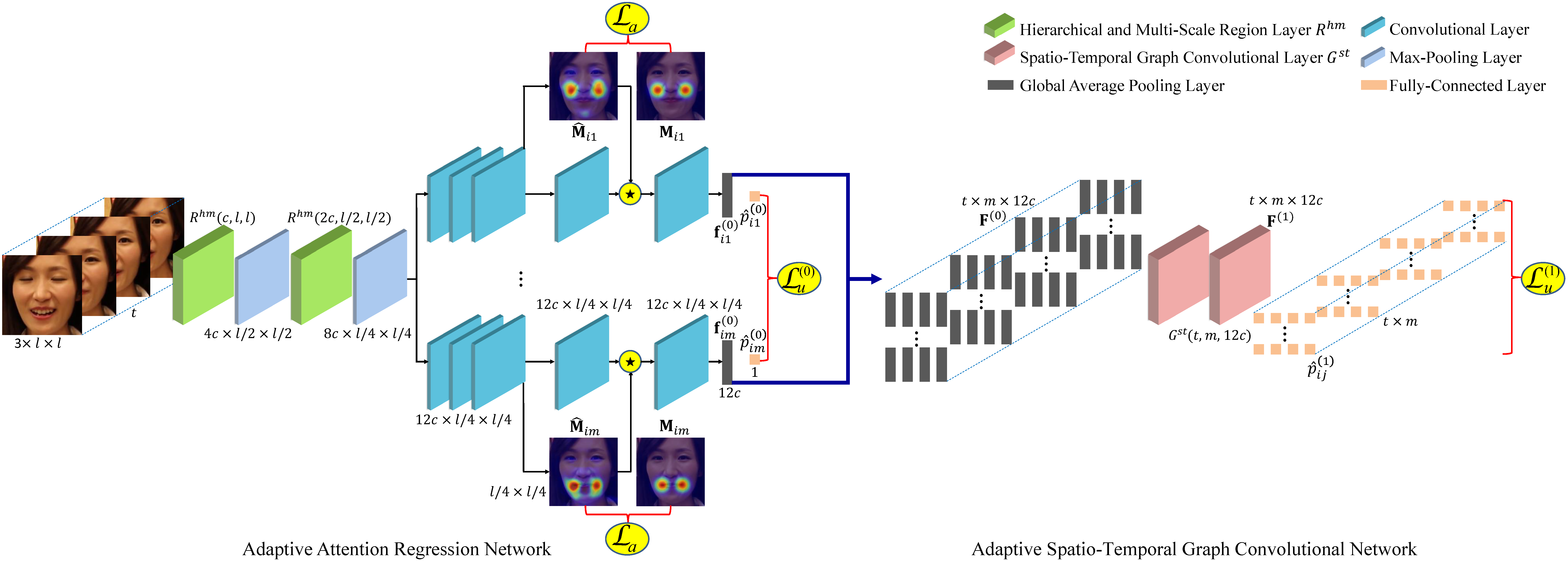
We propose a novel adaptive attention and relation (AAR) framework for facial AU detection. Specifically, we propose an adaptive attention regression network to regress the global attention map of each AU under the constraint of attention predefinition and the guidance of AU detection, which is beneficial for capturing both specified dependencies by landmarks in strongly correlated regions and facial globally distributed dependencies in weakly correlated regions. Moreover, considering the diversity and dynamics of AUs, we propose an adaptive spatio-temporal graph convolutional network to simultaneously reason the independent pattern of each AU, the inter-dependencies among AUs, as well as the temporal dependencies.
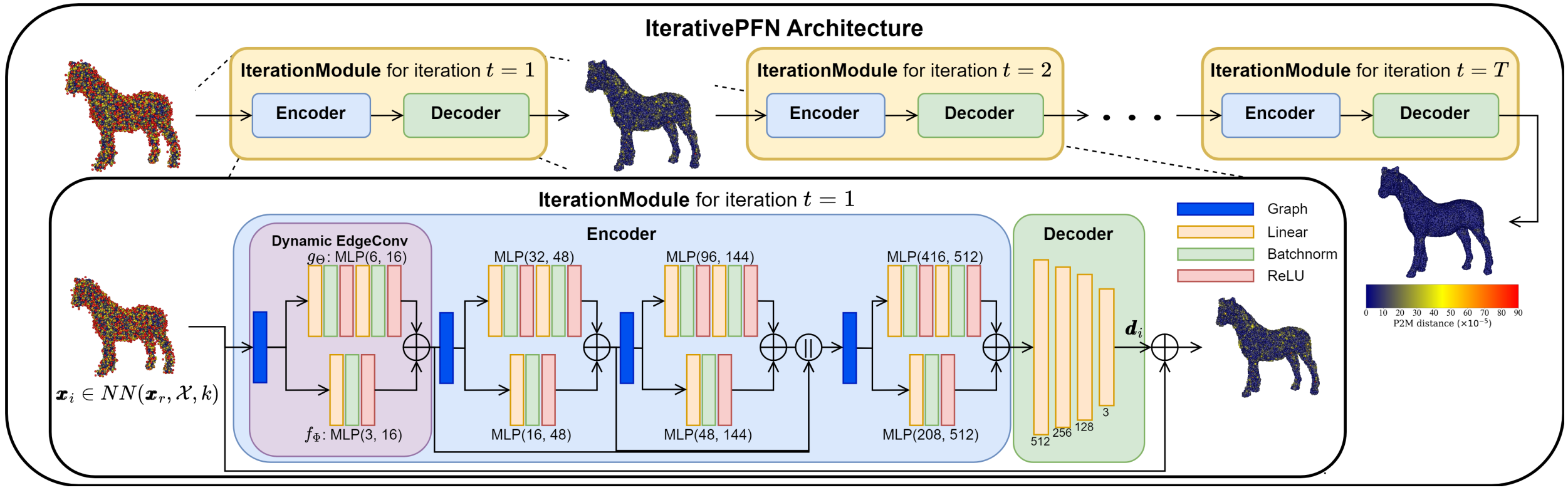
We propose IterativePFN (iterative point cloud filtering network), which consists of multiple IterationModules that model the true iterative filtering process internally, within a single network. We train our IterativePFN network using a novel loss function that utilizes an adaptive ground truth target at each iteration to capture the relationship between intermediate filtering results during training. This ensures filtered results converge faster to the clean surfaces.
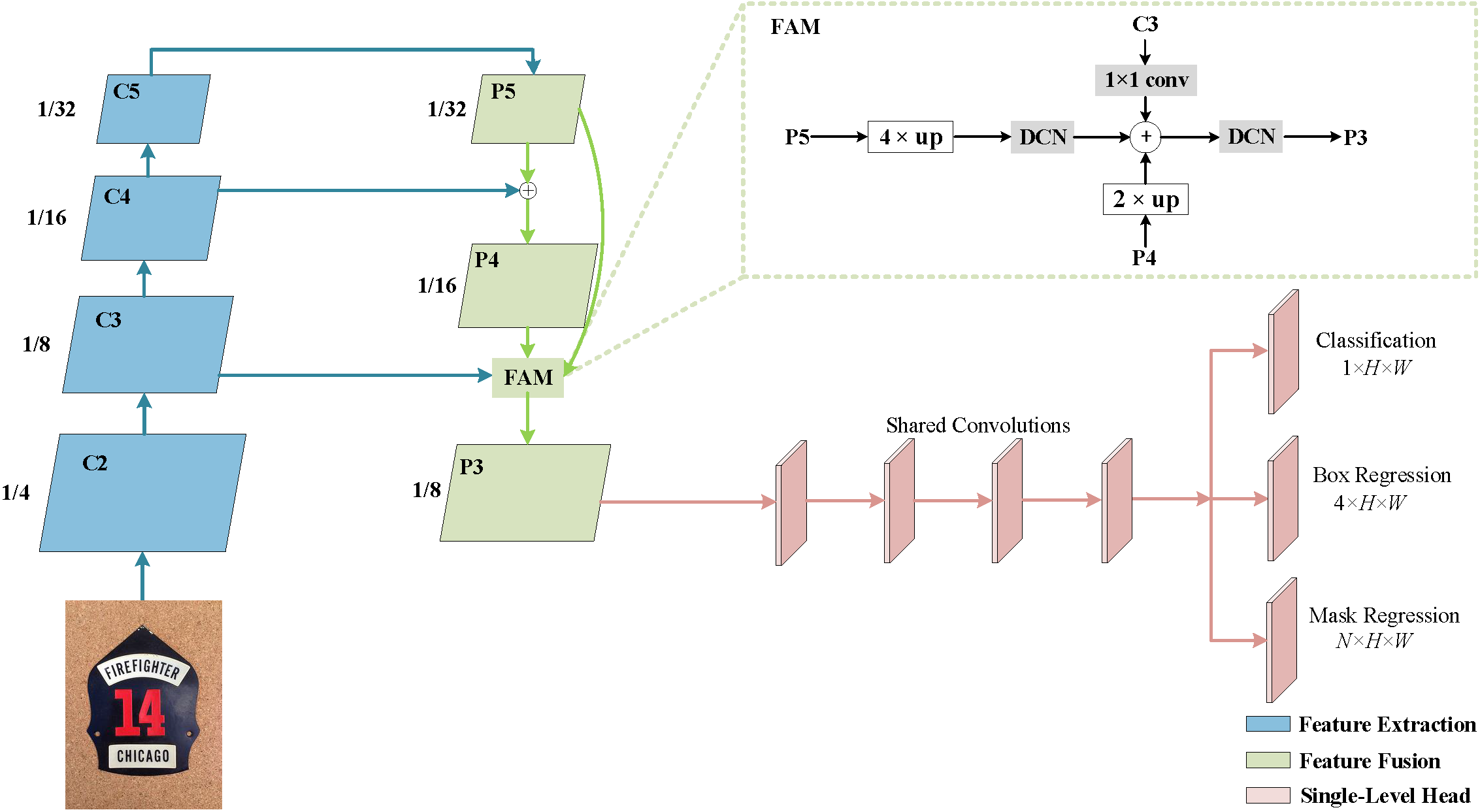
We propose a novel light-weight anchor-free text detection framework called TextDCT, which adopts the discrete cosine transform (DCT) to encode the text masks as compact vectors. Further, considering the imbalanced number of training samples among pyramid layers, we only employ a single-level head for top-down prediction. To model the multi-scale texts in a single-level head, we introduce a novel positive sampling strategy by treating the shrunk text region as positive samples, and design a feature awareness module (FAM) for spatial-awareness and scale-awareness by fusing rich contextual information and focusing on more significant features. Moreover, we propose a segmented non-maximum suppression (S-NMS) method that can filter low-quality mask regressions.
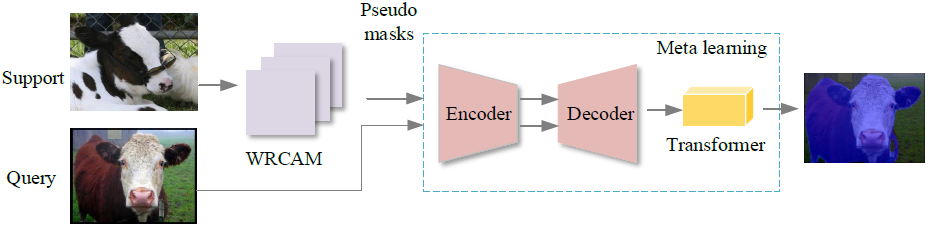
We propose a weakly supervised few-shot semantic segmentation model based on the meta learning framework, which utilizes prior knowledge and adjusts itself according to new tasks. Thereupon then, the proposed network is capable of both high efficiency and generalization ability to new tasks. In the pseudo mask generation stage, we develop a WRCAM method with the channel-spatial attention mechanism to refine the coverage size of targets in pseudo masks. In the few-shot semantic segmentation stage, the optimization based meta learning method is used to realize few-shot semantic segmentation by virtue of the refined pseudo masks.
Granted Patents
2026: A Method and Device of Egocentric Video Generation Based on Masked Diffusion Model and Gaze Constraint, The First Inventor, ZL202510563430.2
2026: A Method and Device of Egocentric Multi-Face Tracking Based on Gaze Localization and Long-Short Term Modeling, The First Inventor, ZL202510319053.8
2026: A Method and Device of Joint Facial Expression Spotting and Recognition Based on Aggregated Features and Dual Anchoring, The First Inventor, ZL202510352352.1
2025: A Method and Device of Face Recognition Based on Depthwise Separable Convolution and Additive Angular Margin Loss, The Fifth Inventor, ZL202210942319.0
2025: A Method and Device of Face Recognition Based on Depthwise Separable Convolution and Additive Angular Margin Loss, The Fifth Inventor, ZL202210942319.0
2025: A Method and Device of Micro-Expression Recognition Based on Multi-Task Learning and Global Circular Convolution, The First Inventor, ZL202211618464.X
2025: A Method and Device of Facial Action Unit Transfer Based on Deformable Autoencoder and Disentanglement Swap, The First Inventor, ZL202210444149.3
2025: A Method and Device of Scoliosis Recognition Based on Symmetric Perception on Natural Image, The First Inventor, ZL202410850833.0
2025: A Method of Motion-Aware Self-Supervised RGBT Tracking Based on Multimodal Hierarchical Transformer, The Fifth Inventor, ZL202311169927.3
2025: A Method of Adversarial Attacks Guided by Attention for Video Object Segmentation, The Sixth Inventor, ZL202210080615.4
2025: A Method of Unsupervised RGBT Object Tracking Based on Attentional Multimodal Feature Fusion, The Seventh Inventor, ZL202210138232.8
2024: WeChat Mini-Program V1.0 for Scoliosis Recognition Based on Symmetric Visual Perception on Natural Image, Software Copyright, The First Inventor, 2024SR1646431
2024: Drowning Behavior Analysis Method and Anti-Drowning System Based on Multi-Object Tracking and Recognition, The First Inventor, ZL202410624672.3
2024: Anti-Drowning Safety Management System V1.0 in Swimming Venue Based on Multi-Object Tracking and Recognition, Software Copyright, The First Inventor, 2024SR1027205
2024: An Online Exam Cheating Prevention System Based on Facial Emotions and Multiple Behavioral Features, The First Inventor, ZL202310884470.8
2023: A Method and Device of Facial Action Unit Recognition Based on Adaptive Attention and Spatio-Temporal Correlation, The First Inventor, ZL202210606040.5
2022: A Method and Device of User Personality Characteristic Prediction Based on Multi-Modal Information Fusion, The Third Inventor, ZL202111079044.4
2021: A Method and Device of Facial Action Unit Recognition Based on Joint Learning and Optical Flow Estimation, The First Inventor, ZL202110360938.4
2018: Identity Verification System V1.0 Based on Face Recognition, Software Copyright, The Second Inventor, 2018SR160441
Teaching Experiences
2023 - Present: Introduction to Information Science, Lecturer
2022 - Present: Image Processing and Computer Vision, Lecturer (Principal of Course)
2022 - Present: Practice for Python Programming, Lecturer
2021: Computational Thinking and Artificial Intelligence Foundation, Teaching Assistant
2020: Practice for Computational Thinking and Artificial Intelligence Foundation, Lecturer
2020: Technology of Cloud Computing and Big Data, Teaching Assistant
2020: Introduction to Information Science, Teaching Assistant
Academic Services
Area Chair: ACM International Conference on Multimedia (MM) 2024, 2025
Associate Editor: The Visual Computer (TVC)
Publication Chair: Computer Graphics International (CGI) 2023
Session Chair: Computer Graphics International (CGI) 2022, Shanghai Cross-Media Intelligence and Computer Vision Forum 2019
Member in Chinese Association for Artificial Intelligence (CAAI): Professional Committee of Pattern Recognition, Professional Committee of Knowledge Engineering and Distributed Intelligence, Professional Committee of Machine Learning
Member in China Society of Image and Graphics (CSIG): Professional Committee of Machine Vision, Professional Committee of Animation and Digital Entertainment
Member in JiangSu association of Artificial Intelligence (JSAI): Professional Committee of Pattern Recognition, Professional Committee of Uncertain Artificial Intelligence
Program Committee Member/Conference Reviewer: CVPR, ICCV, ECCV, IJCAI, AAAI, ACM MM, CGI, ICONIP, ICIG, NCIIP
Journal Reviewer: IEEE TPAMI, IJCV, IEEE TIP, IEEE TAFFC, IEEE TMM, Signal Processing, SPIC, IET IP, TVC, Computers & Graphics, IEEE Sensors, Journal of Electronic Imaging, Frontiers in Computer Science